Training and Test data
Understanding training and test data in Machine Learning

When machine learning algorithms are used to generate predictions on data that was not used to train the model, their performance is estimated using the train-test split technique. It is a quick and simple process to carry out, and the outcomes let you evaluate the effectiveness of machine learning algorithms for your particular predictive modelling issue.
In this article, will discuss training, testing, and validation datasets as well as how to split our model into training and testing dataset. And mistakes made during splitting dataset.
Training data
The training data is a subset of our actual dataset that is fed into the machine learning model to uncover and learn patterns. It trains our model in this way. Typically, training data is bigger than testing data. This is due to the fact that we want to give the model as much data as possible in order to uncover and learn important patterns. When we feed data from our datasets to a machine learning algorithm, it learns patterns and makes choices.
Algorithms allow computers to answer issues based on previous observations. It’s similar to how people learn through example. The main difference is that robots require many more samples to recognise patterns and learn.
Test data
Once your machine learning model has been developed (using your training data), you will require unseen data to test it. This data is referred to as testing data, and it may be used to assess the effectiveness and development of your algorithms’ training and to alter or optimise it for better outcomes.
There are two primary criteria for testing data. It should:
- Represent the original dataset.
- Be large enough to produce relevant forecasts
As previously stated, this dataset must be fresh and “unseen.” This is due to the fact that your model already “knows” the training data. How it performs on new test data will tell you if it is performing correctly or whether it needs more training data to operate to your standards. Test data is a last, real-world verification of an unknown dataset to ensure that the machine learning algorithm was properly trained.
validation data
The validation set is a different collection of data from the training set that is used to validate the performance of our model during training. This validation method provides data that allows us to fine-tune the model’s hyperparameters and settings. The key purpose behind separating the dataset into a validation set is to avoid our model from overfitting, which occurs when the model gets extremely effective at identifying samples in the training set but is unable to generalise and make accurate classifications on data it has never seen before.
How to split your dataset
so let’s start
the first step is we need to download the dataset and then apply the dataset to the model. you can download or copy data from the URL —
https://raw.githubusercontent.com/aviralb13/git-codes/main/datas/Health_insurance.csv
Importing the libraries
Now we will import pandas and NumPy as shown below. If your system does not have these libraries installed, you may get them using the pip command.
Now we have to import sklearn.modelselection to use train and test split function
Now the first 4 values (train_x,test_x,train_y,test_y) are the name we have to give to our new data after splitting. If you don’t understand just refer to the image below.

Here, we are providing three parameters: x, y, and the dataset, where x is the feature and y is the label. Since the train size is set to 0.8, the dataset will be divided into two parts: training and testing, with 80 being the training dataset and 20 being the testing dataset.
Mistakes made during splitting dataset
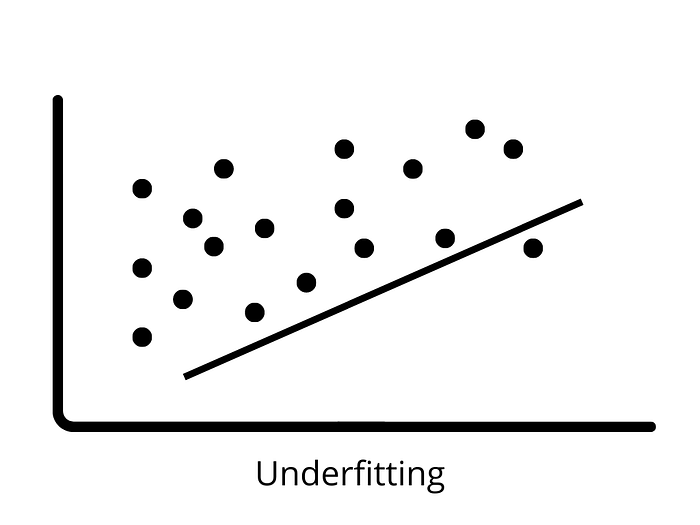
Underfitting
Underfitting happens when a model has not learned the patterns in the training data properly and is unable to generalise adequately on the new data. An underfit model performs badly on training data and makes erroneous predictions. Underfitting occurs when there is a significant bias and a low variance.
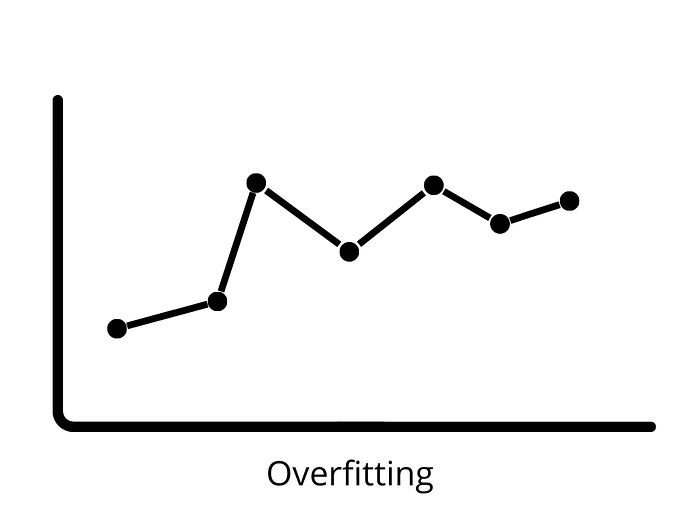
Overfitting
Overfitting happens when a model performs extraordinarily well on training data but badly on test data (fresh data). In this case, the machine learning model learns the details and noise in the training data, which has a negative influence on the model’s performance on test data. Overfitting can develop as a result of low bias and high variance.
You may read my entire article on underfitting and overfitting.
If you like my article and efforts towards the community, you may support and encourage me, by simply buying coffee for me

Conclusion
well I have good news for you I would be bringing some more articles to explain machine learning concepts and models with codes so leave a comment and tell me how excited are you about this.
